
Writing Tips: Finding Web Pages That Are No Longer Online

The Weekly Writing Tips are a collection of best practices for writing and reporting at Global Voices. June's tips are brought to you by Filip Stojanovski, Central and Eastern Europe editor.
Quoting sources is of key importance to establishing credibility, but what to do when a quoted web page ‘disappears'? Sometimes there's a way to find a copy that can still be used for reference.
As I explained in this longer piece on how to find news articles which are no longer available on the websites which have originally published them, online content can disappear for a number of reasons. The website editor might simply remove it, or the whole website might be down, or the website might have been reconstructed in the meantime and the old URLs don't work any more.
The good news is that very often, there are traces of the content that can help you find a useful copy.
The bad news is that this ‘digital immortality’ might work against you, and others can find stuff that you thought you've erased or corrected.
In some cases, especially in regard to public fact-checking, it is very important to enable the readers to see the original content. This might also be useful if you get sued for libel by someone who ‘corrected’ an embarrassing article that you've referred to in its original form. If you have the original URL stored somehow, it might be possible to obtain a copy of the web page at some specific moment in the past. These web page copies, often called “snapshots,” can then help you prove your point, in case of misunderstandings.
A number of web applications, such as search engines and aggregators, keep copies of other people's websites on their own servers, for the purpose of indexing. In some cases, these copies can be accessible and linkable. For instance, Google uses a web crawler (a program that follows the links on the web pages it has already stored) to see what's new on the web. It visits websites and stores their contents in Google's database, to be used by the search engine. Websites called aggregators often use RSS feeds from other, select websites, to see what's new there. And then present the latest news in some easy to access format.
On a global scale, there are two tools that can be helpful in this regard: The Google Cache and Archive.org.
Google Cache
Google Cache enables users to see the previous form of a web page by simply typing “cache:URL” within the Google search bar. It is most useful if you want to check recently changed contents or recently deleted pages. The snapshots in the Cache usually expire after a few days, so if you want to use them to prove a point, you better make a real snapshot of your own, by making a screenshot or using an app that would capture the entire page, like the FireShot extension. The resulting image file can be used at evidence in arguments or embedded within other pages.
The Internet Archive
The Internet Archive (Archive.org) is one of the biggest websites preserving our digital heritage; it has so far saved over 487 billion web pages. Its crawler periodically visits websites, and then its search feature called “The Wayback Machine” enables users to search through these pages by entering their URL. The stored format is HTML, and the links within the stored pages are ‘clickable’ to a certain degree. Also, unlike the Google Cache, the Archive keeps several copies of pages, so you can see how a stored page looked like over time on certain dates. A nifty feature is that any user can also ‘save’ a page by entering its URL using the “Save page now” option.
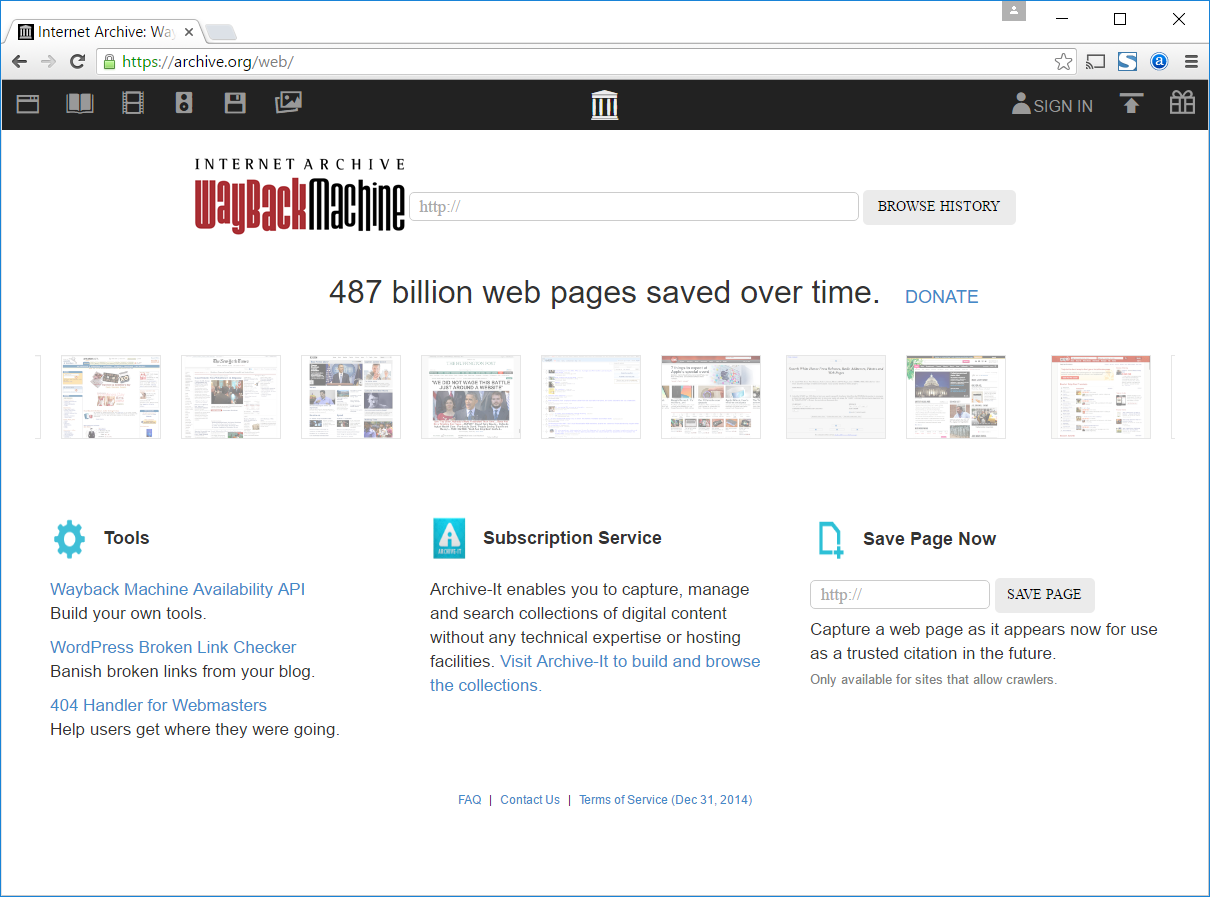
Screen shot of the Wayback Machine from June 6, 2016.
Yandex.ru
Another useful tool in this regard is the Russian search engine Yandex.ru (Яндекс). Due to its predisposition to deal with Cyrilic contents, some times it can harvest different data compared to other search engines from websites in other Slavic languages besides Russian, such as Ukrainian, Serbian, Macedonian or Bulgarian. Each Yandex link comes with a small menu, accessible through the triangle icon, which includes an option of showing a “saved copy” (“Сохранённая копия” in Russian).
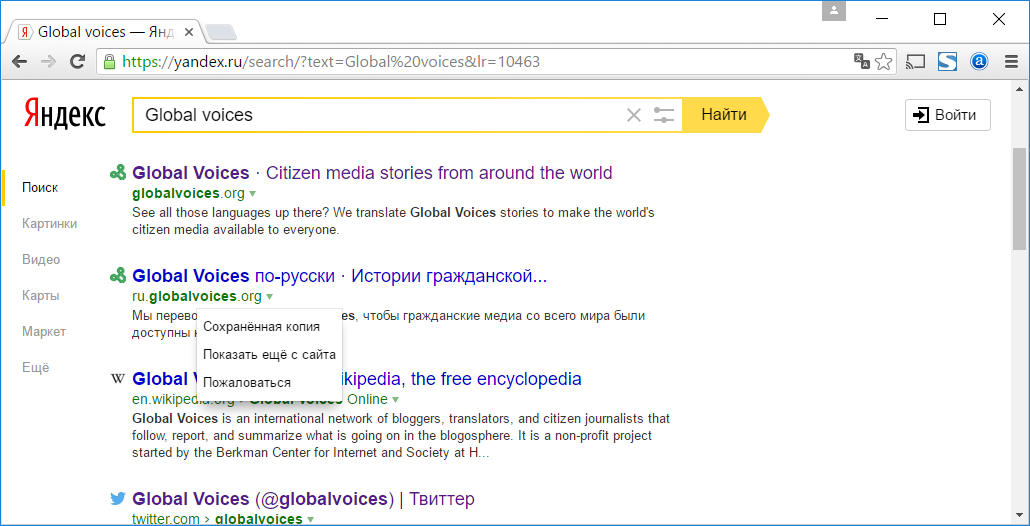
The first option on the menu available for each Yandex.ru link is “stored copy”.
This “saved copy” functions in similar manner as Google Cache, storing a HTML and plain text version of the indexed pages. In the past, this search engine also stored a lot of contents from various blogging platforms, but currently that contents does not seem available.
Options for Macedonian and Albanian languages
However, any of these tools might not work as good as intended all over the world. For instance, there might be parts of the internet which are either “off limits” to them, by choice of the website administrators who can restrict access to crawlers (by editing the robots.txt, or by not allowing their servers to receive visitors from certain IPs). Or, the contents that you need might not have been indexed, because there were no other links leading to it within the already indexed pages. Or the RSS mechanism that some aggregators use might have been shut down by the website administrator. Some times, even the language or the geographical location of the website might play a role. How could Archive.org have ‘known’ that a certain website in Slovakia is worth preserving when it came out in 2003?
In some cases, especially when dealing with content that is not in English, there are peculiarities that are known by people belonging to a certain language/cultural sphere. For instance, people searching for media produced web content in the Macedonian language often find far more data by using the specialized aggregators such as Time.mk or Grid.mk than using Google. Time.mk also offers its own Archive where it stores contents from active websites, but also from websites that have been shut down, like the one of A1 TV.
For Albanian-language content, similar alternatives are Time in Albanian and Fax.al. Even when such websites do not store publicly available copies of the webpages, they can provide you with the original URLs, which can be then input into the Wayback Machine or Google Cache.
Another tool that stores media contents produced in Macedonia in these two languages, plus English, is the Time Machine, developed as part of the Media Fact-Checking Service. The service produces article reviews and within each review it provides the link to the original article on its own website, but also a snapshot (picture) of how it looked like when published and some time after. The Time Machine automates this process by harvesting articles from select websites, making snapshots in text and image formats. This provides grounds for comparisons of different versions of individual articles, but also comparisons of similarities between articles that have been copy-pasted by different websites. This added functionality makes this tool useful in tracking plagiarism, as well as analysis of distribution of propaganda messages from one source via various outlets.
Most countries have similar examples of local agreggators that often serve as starting point, catering to users using their local languages or confined to media read by the local audiences.
None of these methods is fool-proof, and sometimes it is really hard or impossible to find public traces of ‘vanished’ contents, especially if the whole websites went offline. However, considering that all communication via the Internet is based on copying contents from one computer to another, we can assume that multiple stored copies could exist somewhere, including some sort of temporary buffers or secret government/intelligence agencies databases. It is possible that in the future more advanced search engines (possible based on AI – Artificial Intelligence) would be able to “dig out” that contents, too.

